ChatGPT and other generative artificial intelligence tools have come up a lot in the news and libraries have been focusing on its impact. In this blog post, we feature 4 librarians to talk about their thoughts on ChatGPT, generative AI tools, and what they are seeing from a global perspective. Here are our responders from CPDWL Standing Committee and one special guest:

Dr. Almuth Gastinger, Senior Academic Librarian, Norwegian University of Science and Technology (NTNU) in Norway and CPDWL Secretary 2021-2023.

Rajen Munoo, Head, Learning Services & Research Librarian, College of Integrative Studies, Li Ka Shing Library, Singapore Management University (Singapore) and CPDWL Standing Committee Member 2019-2023.

Dr. Leo S. Lo, Dean and Professor of the College of University Libraries and Learning Services (CULLS), University of New Mexico (United States).

Dr. Ray Pun, Academic and Research Librarian, Alder Graduate School of Education, (United States), CPDWL Standing Committee Member 2019-2023.
Question 1: How is ChatGPT and other generative artificial intelligence tools impacting you, your workplace, libraries, institutions, or country?
Almuth: I myself have no experience with ChatGPT or any other AI tool. But colleagues in Norwegian libraries are discussing that topic, of course. At the end of April we had a seminar with “Libraries’ Network for PhD support” in Norway ((mainly academic librarians) where we had several presentations and discussions about ChatGPT and KI tools. Before that seminar some colleagues did a little survey and the results were interesting. Among others, 23% of the respondents (57) have never got any question about KI tools while about 50% have got questions from either researchers or library colleagues. About 35% have even taught a KI tool (i.e. ChatGPT, Keenious, Transkribus, Elicit). However, almost 70% answered that they know AI tools only a little bit, while 23% said they have quite good knowledge.
A few weeks ago there was a discussion on our library listserv about students wanting to borrow books that do not exist. They had got tips for these books from ChatGPT, but have not checked whether they really existed. At the University of Bergen Library a working group called “Artificial intelligence for the support of teaching” was established that organises various events and offers lectures. The topic of KI is also discussed in library blogs and library magazines. At the university level the discussion is focusing on what to do regarding assignments and exams. That is mainly going on between the university administration and teachers/professors. Today (10 May) the university decided that it is not allowed to use ChatGPT during an exam.
Rajen: With the buzz in the air, everyone is chatting about ChatGPT within the university and professionally amongst colleagues in Singapore. I have been educating myself on this fast moving application and compendium of evolving generative AI tools by attending talks and seminars. Whilst we are threading pieces of comments, opinions and reactions, personally I have been looking for some teachable moments to advocate the role of librarians in information and digital literacy and imparting critical thinking.
As a fast mover, Singapore Management University (SMU) sent out a early communique to the Faculty providing more information about this trending topic and followed up with a proposed framework noting that the university recoginises the need to embrace the fast moving and evolving nature of the technology in teaching and learning whilst at the same time being alert to misuse and safeguard academic integrity and standards of academic rigour. They further noted that we are preparing students for the world of work where AI and digital transformation is becoming more pervasive. A whole-of-university approach has been adopted as noted from the stakeholder initiatives below:
The Centre for Teaching Excellence began a series of webinars for Faculty and the SMU educator community such as Let’s Chat!: Rethinking assessment design and detection tools in the age of AI-driven chatbots and Let’s Chat Together: Innovating Teaching in the Age of AI Tools. They also curated resources for self-directed learning: https://cte.smu.edu.sg/resources/use-of-AI-tools I have attended them and found them insightful especially around discussions on plagiarism detection and assessment design. The Student Success Centre is leading the development of a learning object for students on the effective use of AI. The objectives of this course will be to:
- Clarify expectations on how students should use AI responsibly in SMU
- Enable students to use AI appropriately for academic success
- Encourage students to be more thoughtful about using AI tools for learning and growth
SMU Libraries will be contributing content for the topic on Researching with AI and we are excited to be part of this initiative. There are many professional development and knowledge acquisition opportunities taking place in Singapore such as the joint Library Association of Singapore’s (LAS) and National Library Board’s (NLB) upcoming professional sharing in May has as its theme, “Artificial Intelligence and Libraries: Building Future-Ready Information Spaces”.
Ray: I think for me, it’s been interesting to hear the different tensions occurring on various levels. Student Affairs supporting students with disabilities may find this tool to be really helpful. Faculty in writing programs might disagree and see this tool as a threat towards developing academic writing skills critically. At my institution, I am collaborating with faculty members and a student who has a PhD in computer science to talk about where we are on this. There are opportunities but also the potential risks to consider. These AI tools are already embedded and/or will be embedded in many tools we use such as Slack, Google Drive, etc…
Leo: I am fascinated by generative AI. I mostly use ChatGPT and Mid-Journey. And I try to experiment with different ways of prompting to see what kind of responses I get. I have been talking non-stop with my library co-workers about these tools since ChatGPT came out, and I think more and more of them are taking it seriously now. I truly believe that we have entered a brand new era that most people in the world are not ready for. It has completely disrupted education, for example. This is a once in decades kind of opportunity for academic libraries to take a real leadership role at the university level, and I hope we don’t squander it. I am definitely working hard to lead my university’s AI effort.
Question 2: From your point of view, what are some opportunities utilizing ChatGPT in libraries?
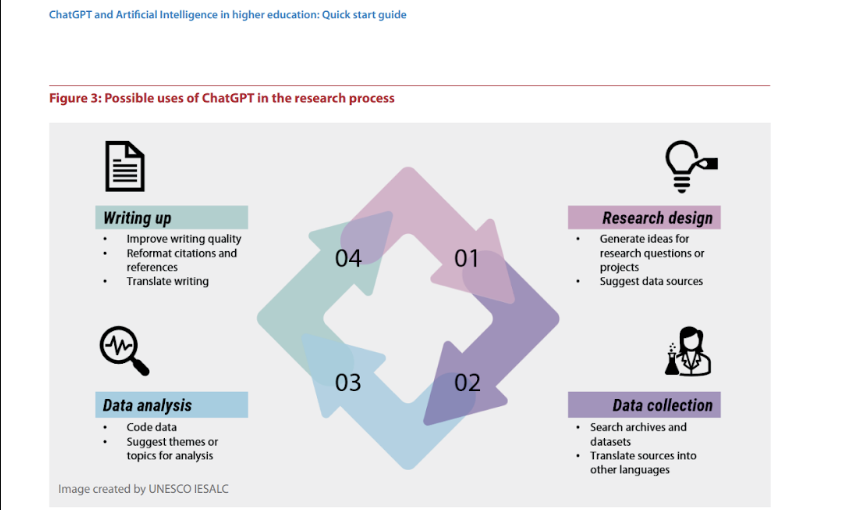
Rajen: Sometimes librarians need help in their own writing and thoughts and I hear of some colleagues using ChatGPT for ‘first drafts’ or let’s see what ChatGPT comes up with. A colleague used it to get some ideas to write a welcome message to freshmen. Personally, I used ChatGPT to compose a poem in Hindi and it delivered! It could be used to help address ‘writer’s block’. Another colleague queried for recommendations for finance databases which referenced SMU Libraries research guides ironically! It could be used as a companion to answering simple quick reference type enquiries and might I add, some fact-checking will be needed. I liked this graphic from UNESCO’s Quick Start guide which highlights the different opportunities for libraries in the research process which I think we can all adapt and contextualise.
Ray: Some opportunities include ways to help students think about complex ideas in different ways. I know for many, reading academic texts can be challenging, it’s important to think about how tools like this can support student learning but there’s also some other issues which I know we will talk about later. Some libraries may potentially consider using ChatGPT as a way to support technical services work such as creating catalog records. Although I don’t think it will replace people doing the work but it may help facilitate the process.
Leo: One potential opportunity is in metadata and cataloging, where ChatGPT can potentially streamline the process. Also, ChatGPT could be an invaluable resource in assisting users with formulating research questions and selecting topics, providing guidance and support throughout their academic journey. I used it to help me develop a study from really a vague idea all the way to having a survey and the IRB done in about an hour. That’s something that would normally take me days or even weeks!
One of the big strengths of ChatGPT is its amazing ability to synthesize and summarize textual content, including reports and emails, in a fraction of the time required by human effort. This could lead to increased efficiency in communication and information dissemination within the institution. I have certainly used it frequently for my emails and communication.
Almuth: The above mentioned survey asked “what advantages do you think AI tools have?”. 60-70% of the respondents mentioned the following three benefits: 1. Giving input and ideas for the further development of a project. 2. Increasing effectivity. 3. Helping with writing. About 23% thought that AI tools can help with data analysis. I also know that my colleagues who offer systematic search services use the tool Deduklick to remove duplicates and that it saves a lot of time. I agree with all of that, but I think in any way one has to be critical. I have heard from many friends and colleagues about totally wrong answers that ChatGPT gave on their questions.
Question 3: What are some concerns using AI tools in libraries? What should we be thinking about?
Ray: Privacy and surveillance for sure. We don’t know where the data will end up going by OpenAI and with these “free” accounts, students may have to think about the risk of creating them. Libraries advocate for the value of privacy and anti-surveillance measures, and we need to think about these issues that our students will use…
Leo: When it comes to implementing AI tools in libraries, there are numerous concerns. Aside from privacy, biases, transparency, and accuracy, one of my biggest concerns is AI literacy among users and library workers. It is critical to ensure that all stakeholders have the appropriate skills and expertise to work effectively with AI tools, and to minimize the flaws of those tools.
Developing AI literacy entails providing library employees with the training and resources to comprehend the capabilities and limitations of AI technology, as well as the ethical implications of their use. This expertise will enable library workers to better assist users in exploring AI products and dealing with any challenges that may emerge. Similarly, increasing AI literacy among library users is critical to ensuring that these new tools are fully utilized. Education programs, workshops, and user guides can assist users bridge the knowledge gap and make educated decisions when interacting with AI-powered services. I am in fact about to launch an AI literacy of academic library employees survey, which I hope to give us some insight into what we need to do to improve AI literacy.
Almuth: I think that the use of AI tools has lots of ethical challenges. There is a lack of transparency and AI is not neutral. AI-based answers are often inaccurate and biased. There is also a problem concerning surveillance and privacy.
In the survey I already mentioned before, colleagues responded that they think the biggest challenges are a comprehension of this type of technology (65%), a lack of resources for training (58%), and ethical challenges (88%). We know that many students use ChatGPT in the same way as Google, that means they do not ask themselves very much whether an answer to a question is right or wrong. One colleague said that you need to have a good knowledge of a topic in order to know whether ChatGPT got it right. So AI literacy is key! But who should teach AI literacy? Librarians or teachers? At my university some teachers/professors already announced that they will include AI tools and the “right” use of them in their classes.
One specific problem is how to cite ChatGPT. The APA style team has discussed this question (https://apastyle.apa.org/blog/how-to-cite-chatgpt) and one of the Norwegian tools for information literacy and academic writing (called “Search and Write”) has also included a paragraph about how to write a reference to AI generated text.
Rajen: For me it is about the AI in AI viz Academic Integrity! There are myriad of things related to academic integrity especially in an educational context. That also means a myriad of things to be concerned about. It also depends on the individual and their personal thoughts and values which can become a philosophical conversation depending on whom you talk with and from which part of the world one is. As a professional librarian advocating the need for literacy skills especially in educational contexts with stakeholders is important. I also echo the comments my colleagues mentioned above. We are living in a technologically-enabled world and experiences have shown the good, the bad and the ugly of its applications.
Reflecting on S.R Rangathan’s Five Laws of Library Science below, how do we reframe our mind around AI in our profession?
Books are for use vs AI are for use
Every person his or her book vs Every person his or her AI
Every book its reader vs Every AI its user
Save the time of the reader vs AI save the time of the reader
A library is a growing organism vs AI is a growing organism
I am still thinking…